Reliability ML Lifecycle Management @C3 AI

Role & Duration
Lead Product Designer
4 Months
Highlights & Stage
ML / AI Developer Tool
Enterprise Product
Featured on C3 AI Annual Conference
Shipped 06/2024
Team Structure
Leadership: Vertical C-Suite Reviews
Peers: 2 PM, 3 DS, 3 SME, 1 Eng Lead, 10+ Eng, 2 Partner Teams
Reports: 1 Product Designer
Reliability Model Management is an End-to-end ML lifecycle management workflow that empowers Reliability Engineers to seamlessly create, manage, and monitor machine learning models from data preparation to deployment, enhancing efficiency and scalability for enterprise AI workflows.
Background
The C3 AI Reliability application uses Anomaly Detection Model to predict equipment failures, detect anomalies, and optimize maintenance, helping industries reduce downtime and improve asset performance. While being recognized as one of the top predictive maintenance tool in the market, we realized the following issues from recent customer’s deployments.

Low Contract Renew Rate

Low User Engagement Rate

Poor Asset Scalability
Conducting vision workshop to uncover the biggest opportunities
Thus, I was tasked with PM to co-organize 5 product vision workshops with key stakeholders to identify the biggest product & design opportunities for the new year’s roadmap planning that can help us better fit the current market.

From the product vision workshops, we learned about the biggest opportunity of improvements is related to model training and deployment.
In deployments of C3 AI Reliability, each AI/ML model is applied to a specific asset. When a user wants to configure and train a model for an asset, they need to highly rely on C3’s field team to manually writing python code in Jupyter notebook, which is a time-intensive, iterative process that requires knowledge of the physical system and involves manually adjusting lines of code.
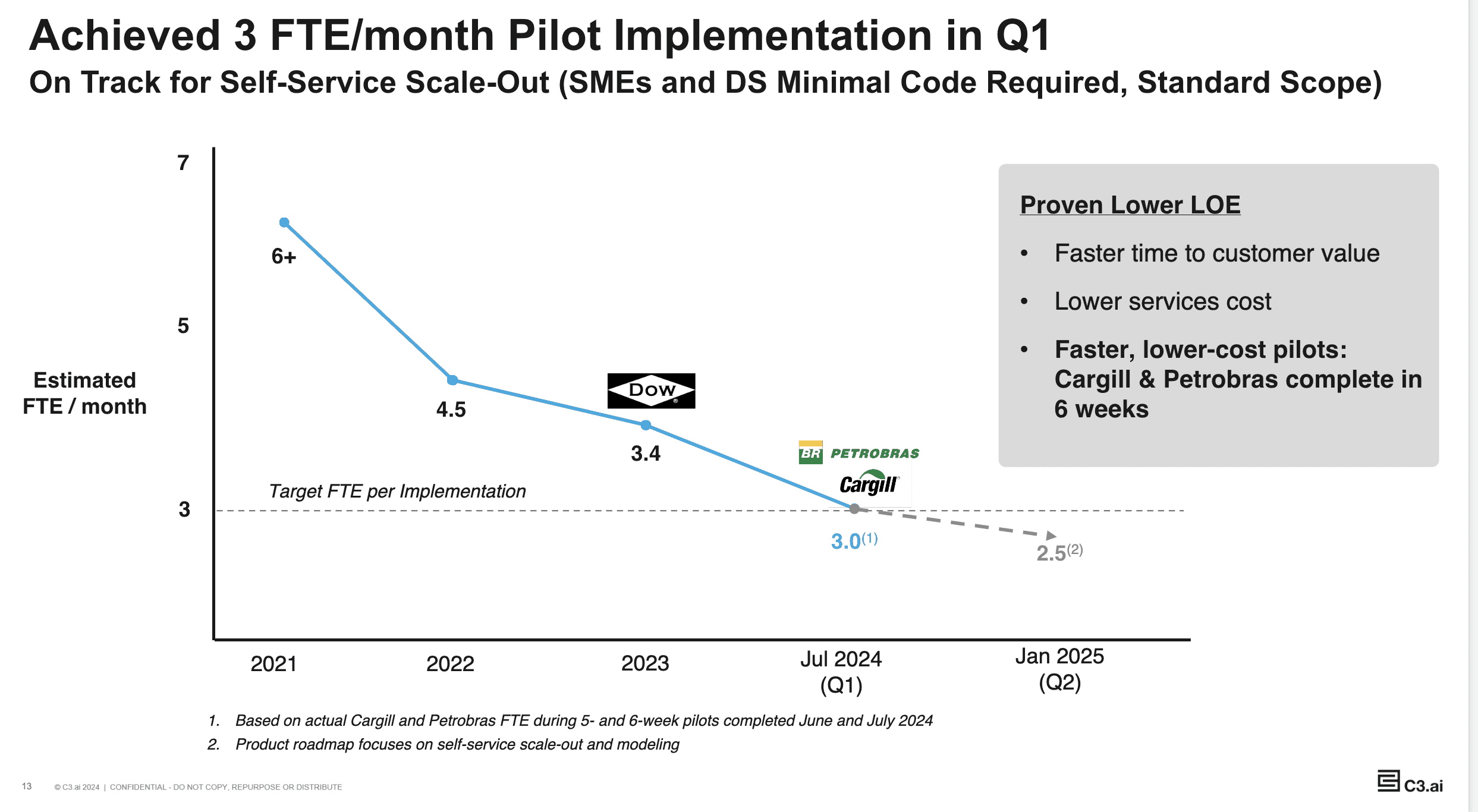
Avg Model Deployment time for 10 Assets
6+ FTE / Month
Setting a Vision for Self-service & reduce deployment time

Final Solution
Introducing Reliability ML Lifecycle Management Module

Alex, a Tesla Reliability Engineer, is tasked with deploying predictive maintenance models across hundreds of electric motors in Tesla vehicles. To ensure operational excellence, Alex must validate sensor data for the entire fleet, prepare a detailed dataset for a specific asset, and configure models efficiently across all motors.
Step 1: Bulk Data Validation
Alex begins by validating sensor data for all motors at once using the bulk data validation feature.
Step 2: Data Preparation for a Single Asset
After completing the fleet-wide validation, Alex focuses on a specific motor that requires detailed tuning for its predictive maintenance model.
Step 3: Bulk Model Configuration
With validated data and a prepared dataset, Alex moves on to deploying models across the entire fleet using the bulk model configuration tool.

Discovery
Identifying key user persona and uncovering pain points in ML lifecycle
With the focus on reduce the ML deployment time, my team and I created a research plan to document our goals and assumptions. We investigated the domain from multiple angles: user interviews with internal field team and external customers, as well as the competitive analysis on similar products.


Imagine C3 is helping Tesla deploy models for 100 cars


Familiarity with ML & Tesla Cars (Assets)
Expert with C3’s framework for ML
Expert on REL ML approaches
Actively developing new models for REL
Not familiar with Tesla Cars at all
Familiarity with ML & Tesla Cars (Assets)
Familiar with basic technical words (“algorithm”, “dataset”)
Unfamiliar with C3’s framework for ML
Unfamiliar with coding
Expert of sensor data for each car
Reponsibilities
Coding in Jupyter to Validate Car Data to make sure car is connected with sensors
Using Jupyter to prepare and clean the data based on Reliability Engineers requirements
Configure Model based on Reliability Engineers requirements
Investigate issues with configuration, training, or deployment of models
Reponsibilities
Define the ML objective (I want to predict potential failure for 100 Cars in my plant)
Tell Data Scientist which sensors need to be included.
Tell Data Scientist which data need to be masked out in dataset.
Evaluate the model performance after training.
Report out on any issues with configuration, training, or deployment of models
So, What’s the problem?
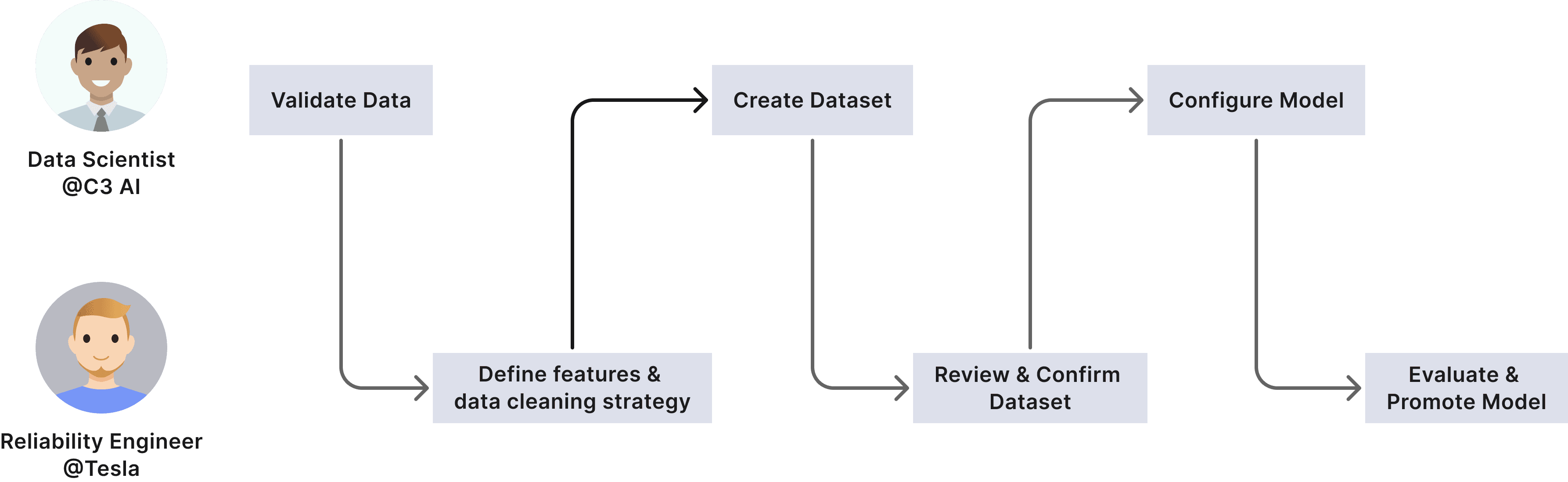
Back and Forth Collaboration Process
High Learning Curve
Dataset Preparation is too manual, high dependent on eng experience
Shaping the strategy
Focus on the primary users, Automating the ML technical part while empowering what the users good at
I explored ways to simplify complex information while keeping core actions clear. Tasked with designing a workflow inspired by Google Vertex AI, I recognized its broad use case might not fit Reliability Engineers. I advocated for user validation to refine the functionality based on real feedback.
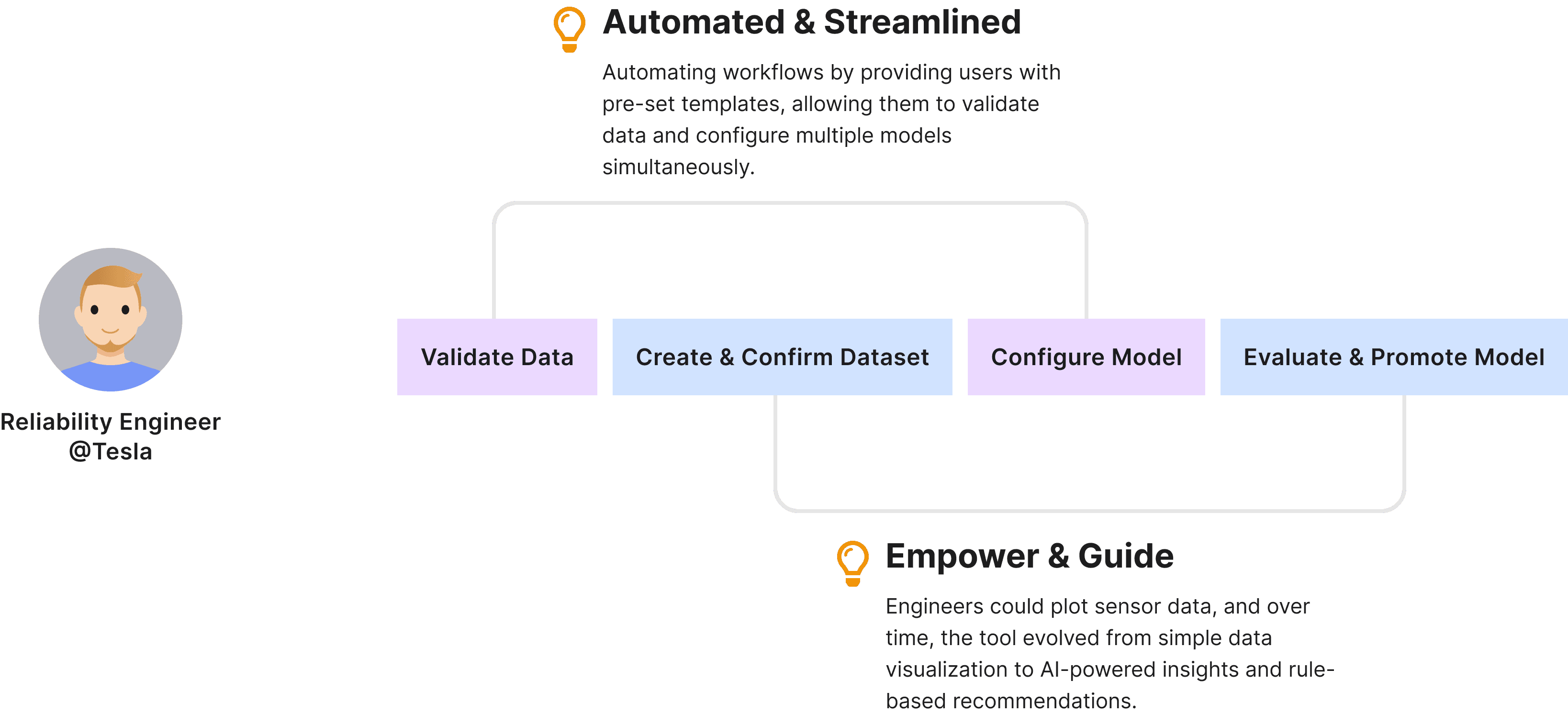
Design Decision 1 - Empower & Guide
HMW simplify complicated dataset preparation while empower users to dive deep?
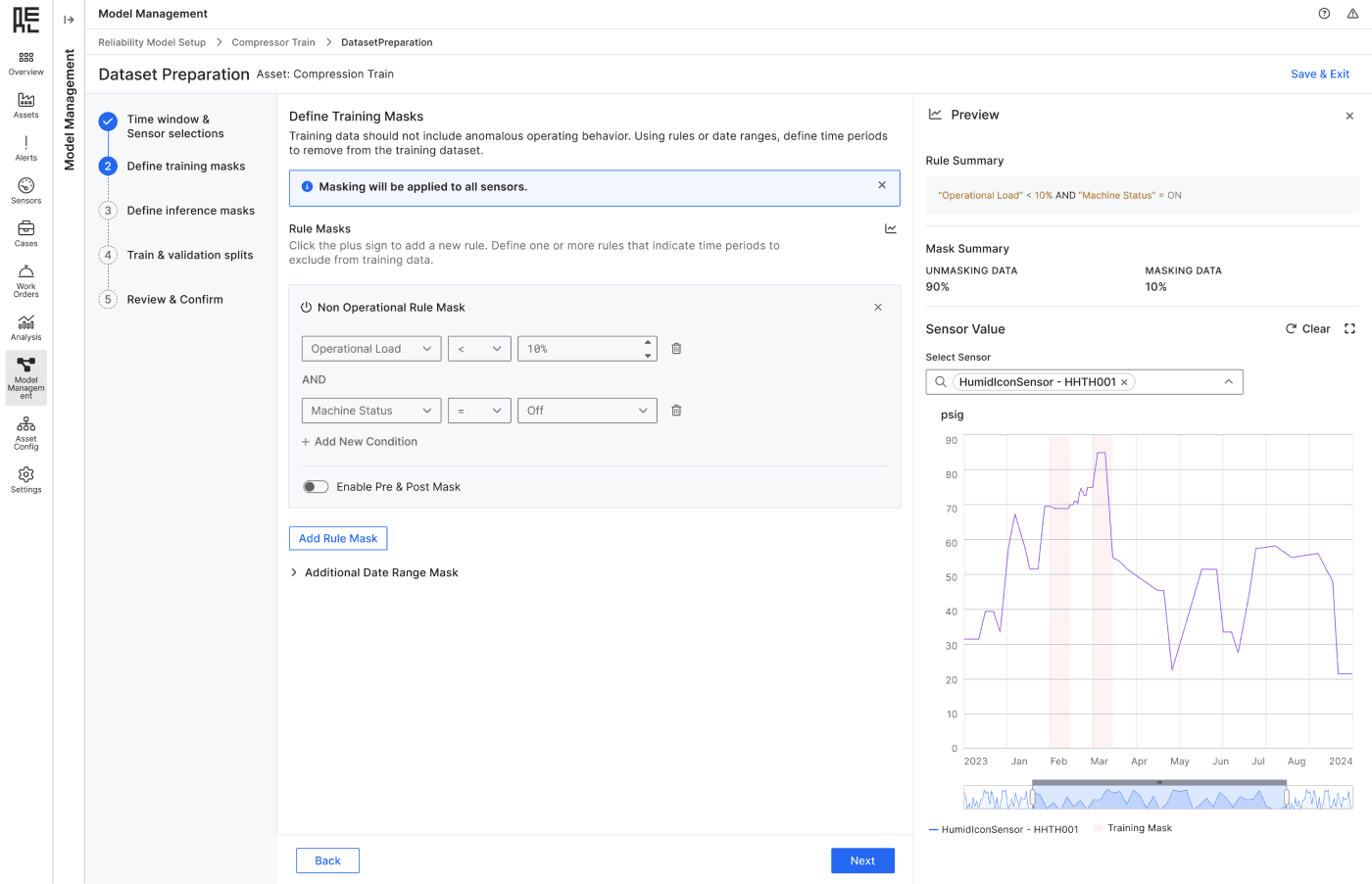
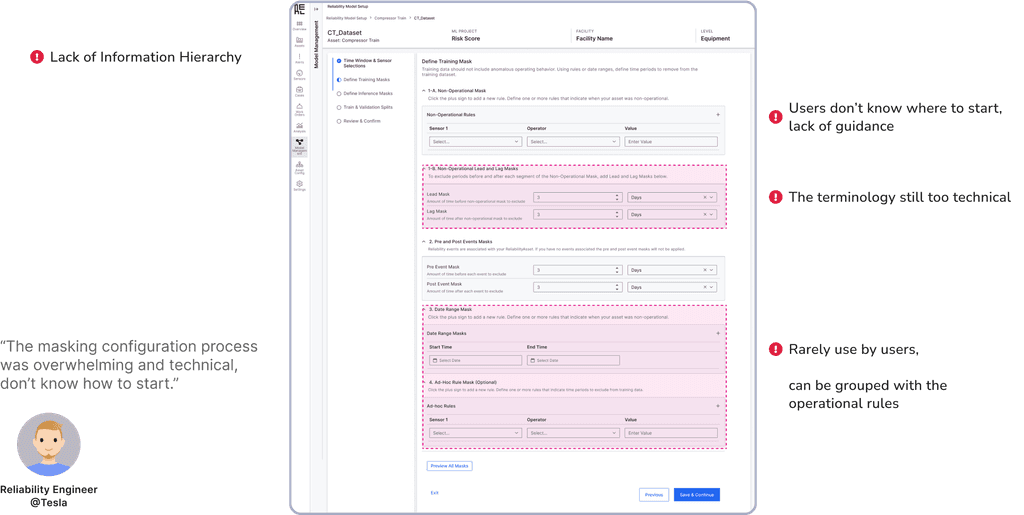
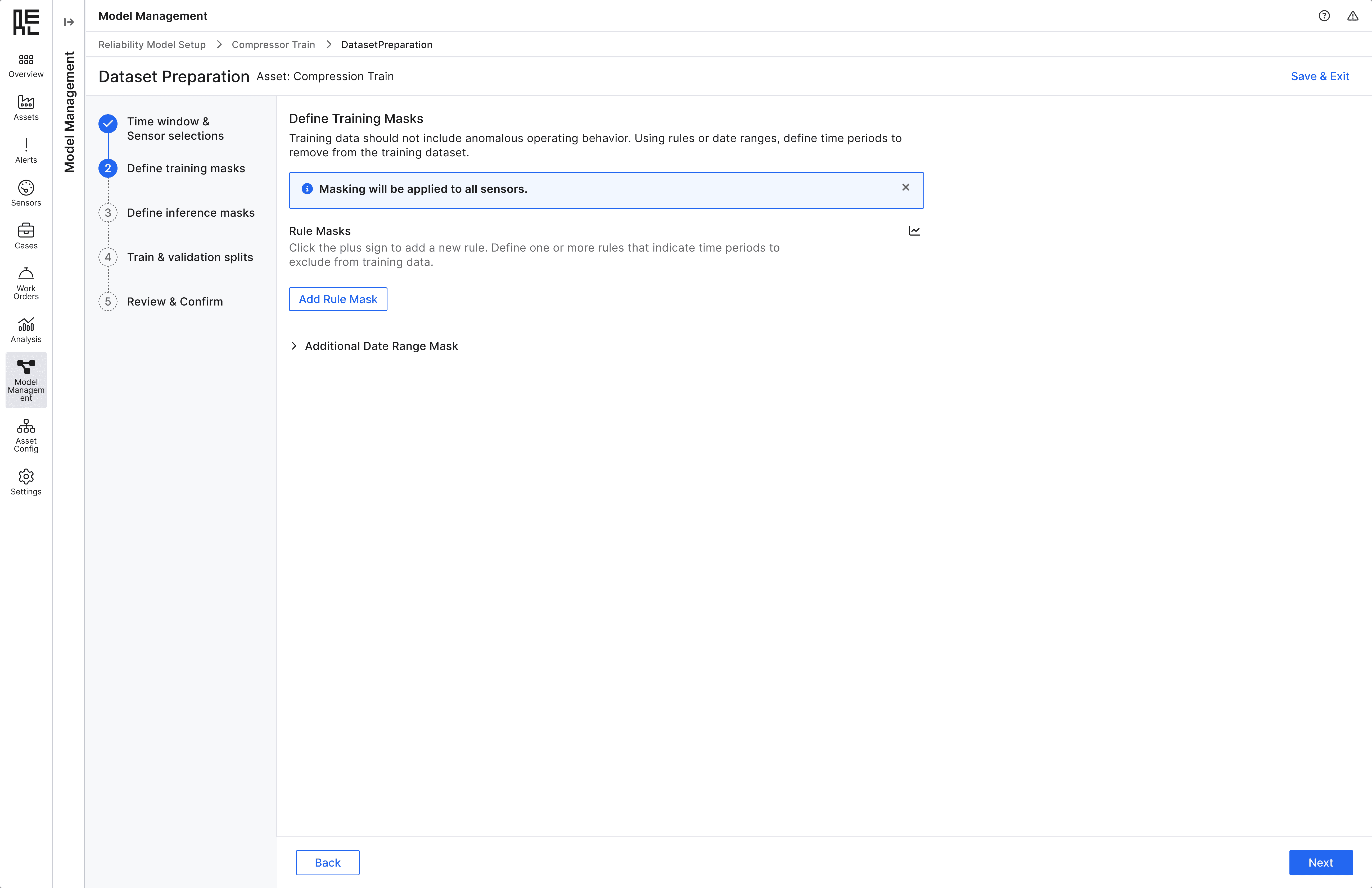
Among all the dataset preparation steps, applying the data masks is the most complicated one.
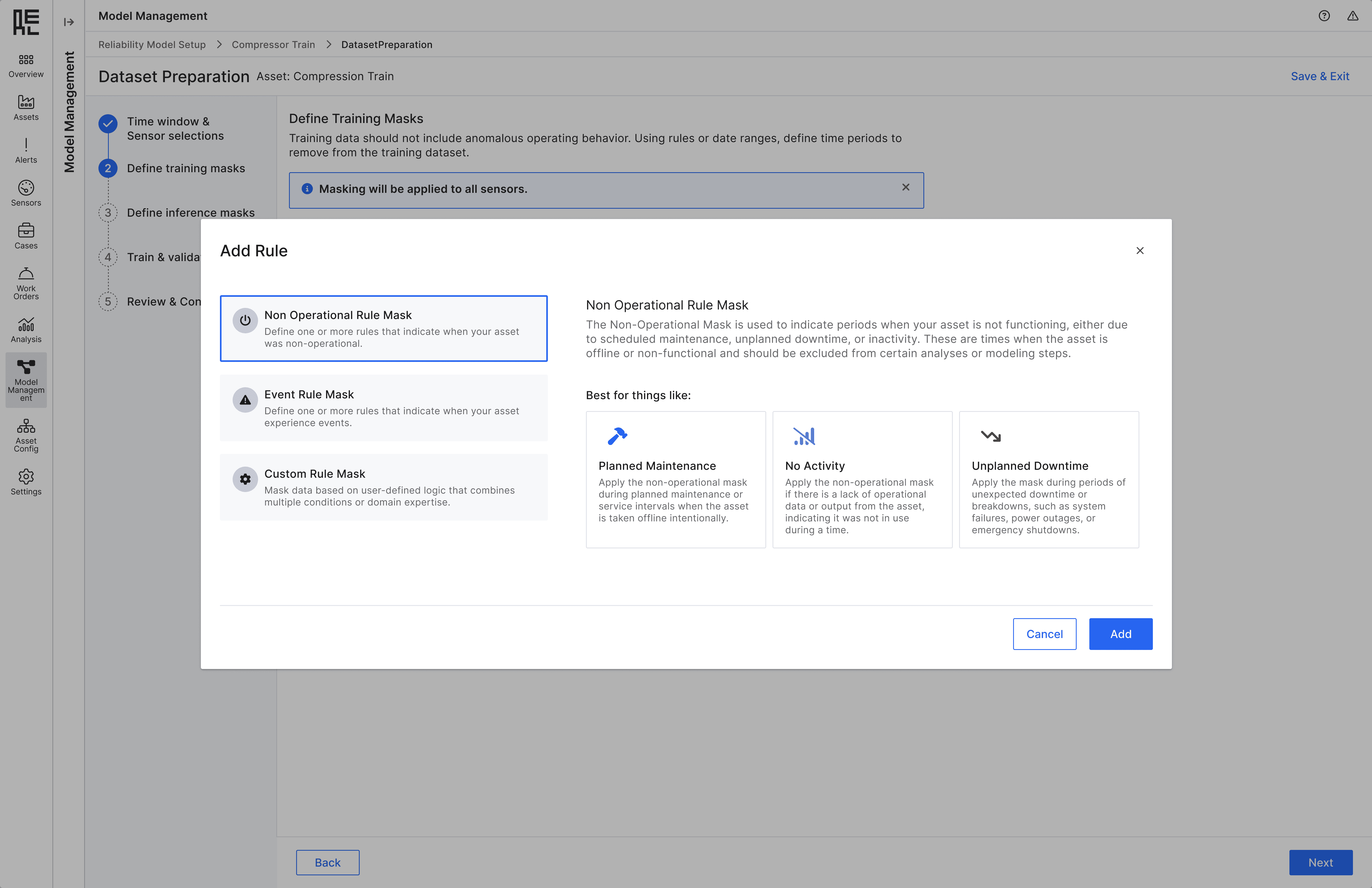
Understand types of masks
I collaborated with data scientist and 2 users from Shell - one of our biggest client to understand the common masking strategies,
Create quick design to validate with users
To gather early feedback, I quickly created a one-page mockup and tested it with users. A key insight was that the masking configuration process felt too overwhelming and technical, leaving most users confused. While my PM suggested adding descriptions and tooltips to guide users, I believed this approach would further increase cognitive load.


Refine the designs
After multiple design iterations and user validation, I focused on simplicity as a core design principle. By organizing input categories into clear sections and using progressive disclosure for advanced inputs, users felt more guided and confident throughout the experience.
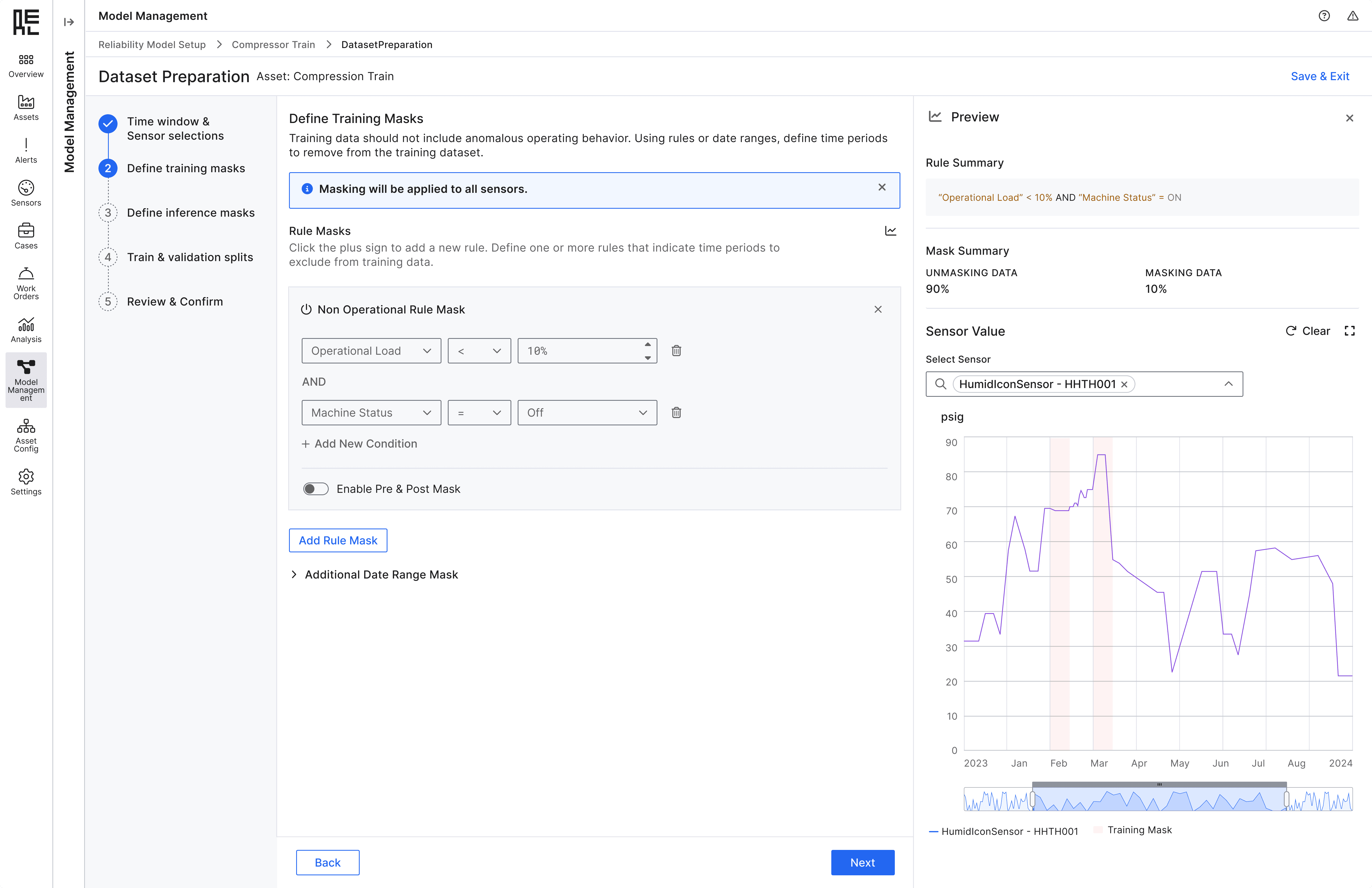

Design Decision 2 - Empower & Guide
HMW help users effectively decide which sensors to include in Dataset?
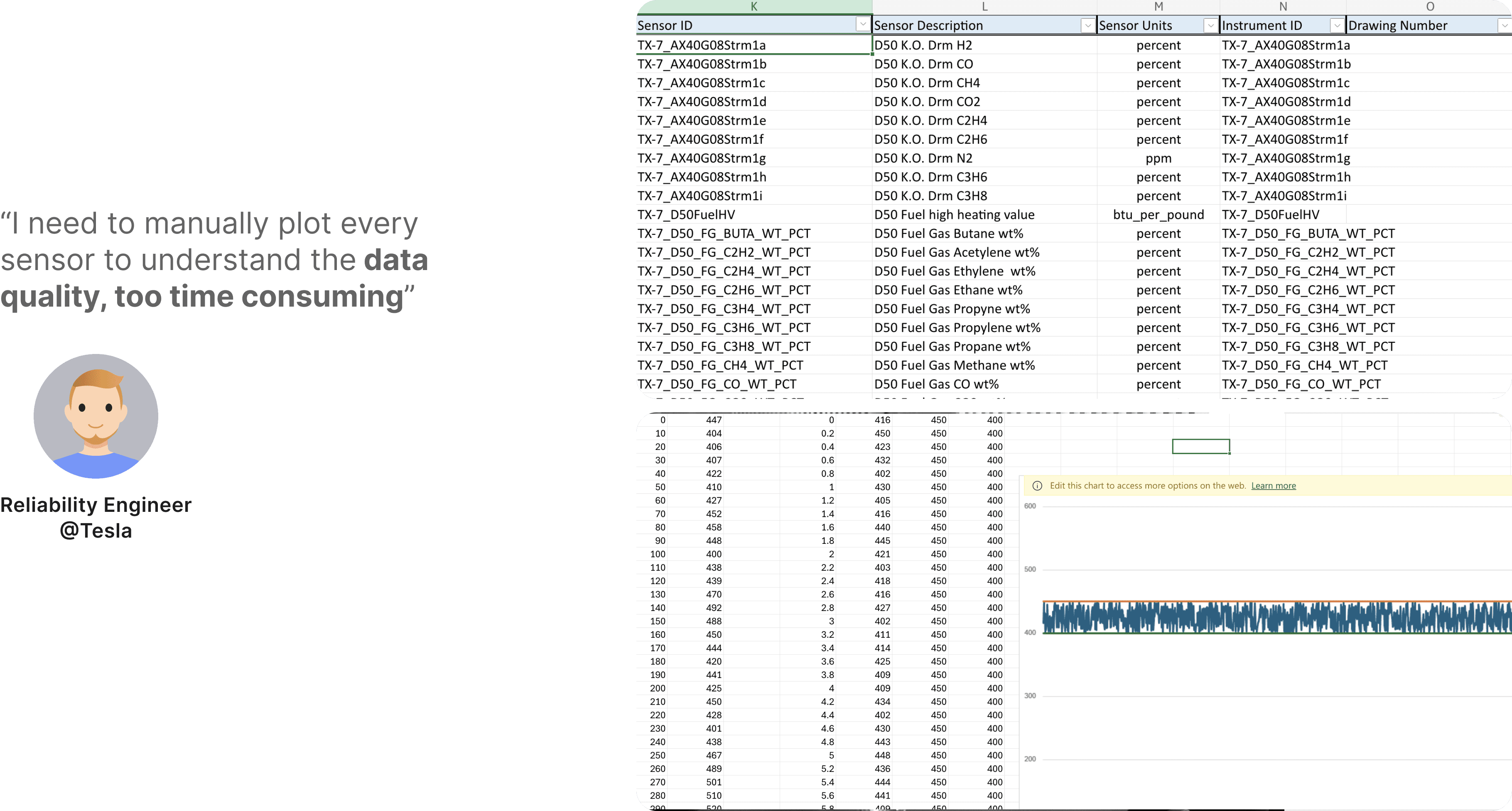
To create a high-quality dataset, users need to select relevant sensors for each asset and ensure those sensors provide reliable data. This requires users to manually review sensor data to confirm it meets quality standards, avoiding sensors with excessive low-variance data, flatlines, outliers, or missing values.
Understand what defines a good sensor data
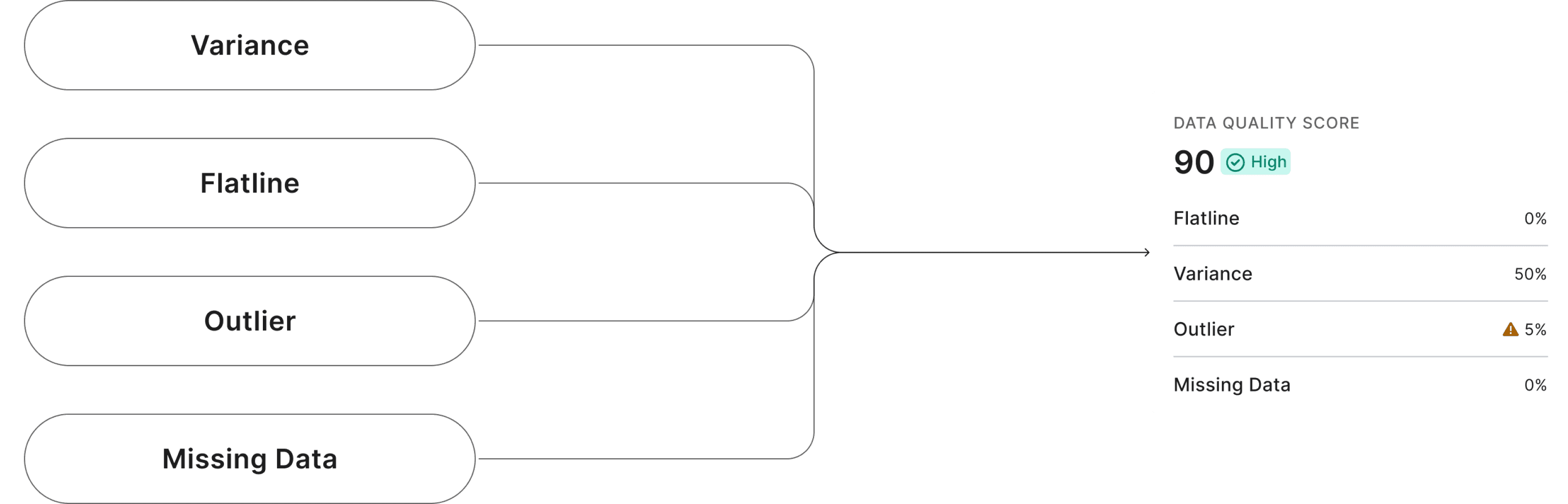
Through the process, I constantly work with data scientist to brainstorm if there are any ways can help users automate sensors with good quality. So I came up with an idea - What if we can leverage AI to generate a data quality score that take variance, flatline, outlier and missing data as model input.
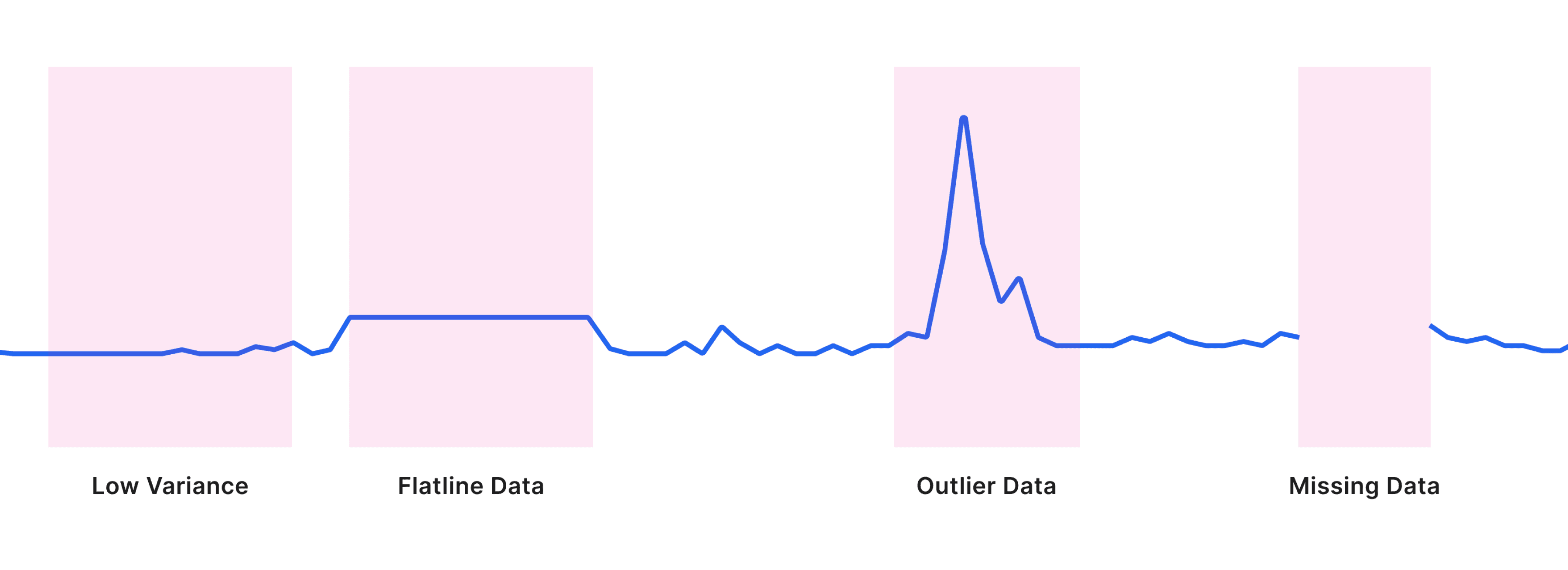
Don't automate just for the sake of it
However, when I presented this concept to both users and data scientists, they raised a valid concern.

Rule-based instead of ML-based
After discussions with data scientists and developers, we decided to implement a straightforward rule-based approach, allowing users to set configurable thresholds for variance, missing data, flatlines, and outliers. This approach also gives users the flexibility to manually add or remove sensors as needed.
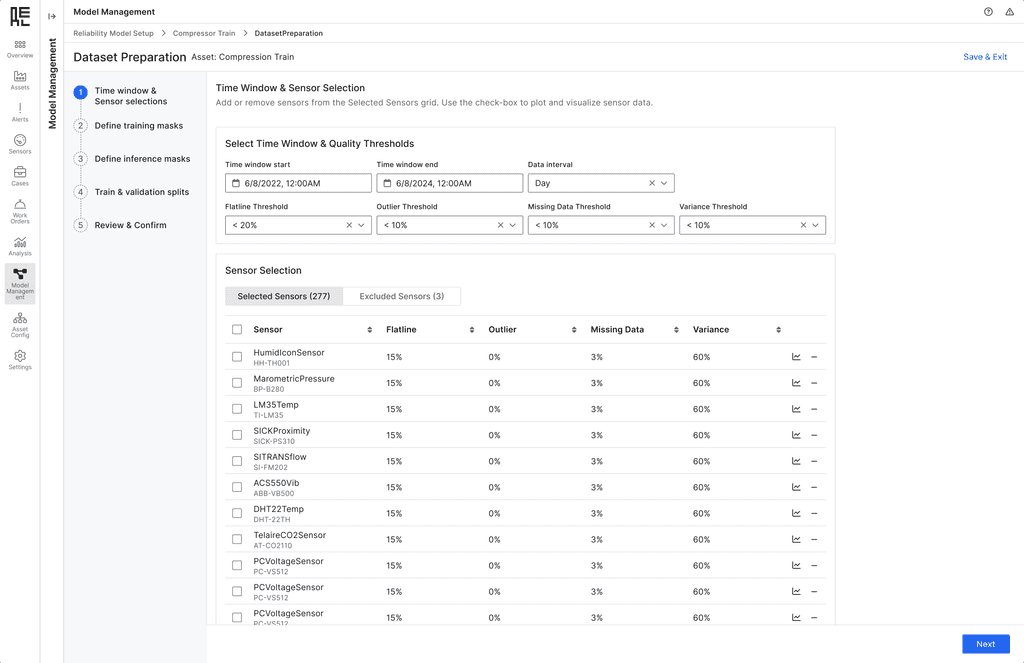
Design Decision 3 - Automate & Streamline
HMW enable users to automate and scale the technical setup of model configurations?
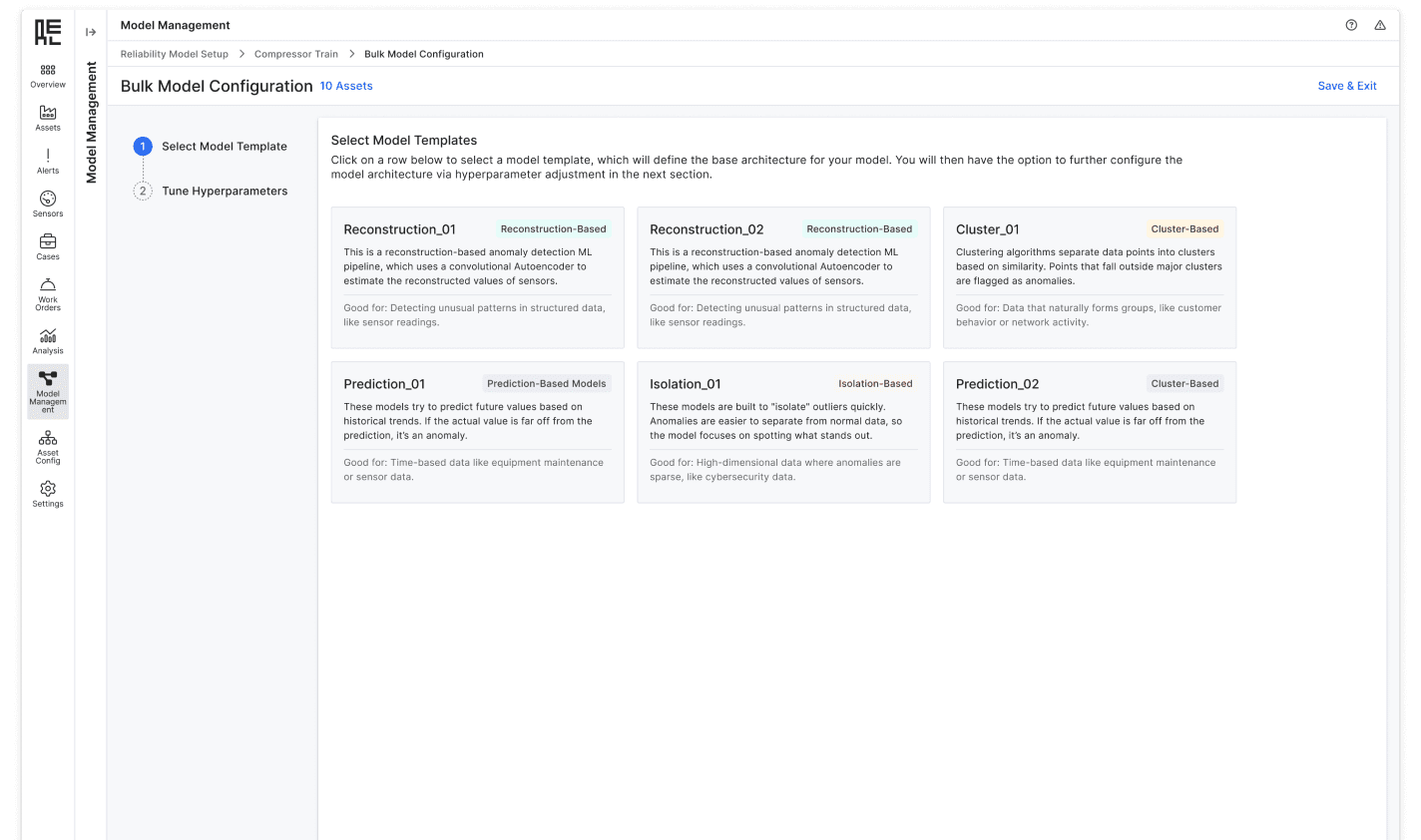
Bulk select assets to start model configuration
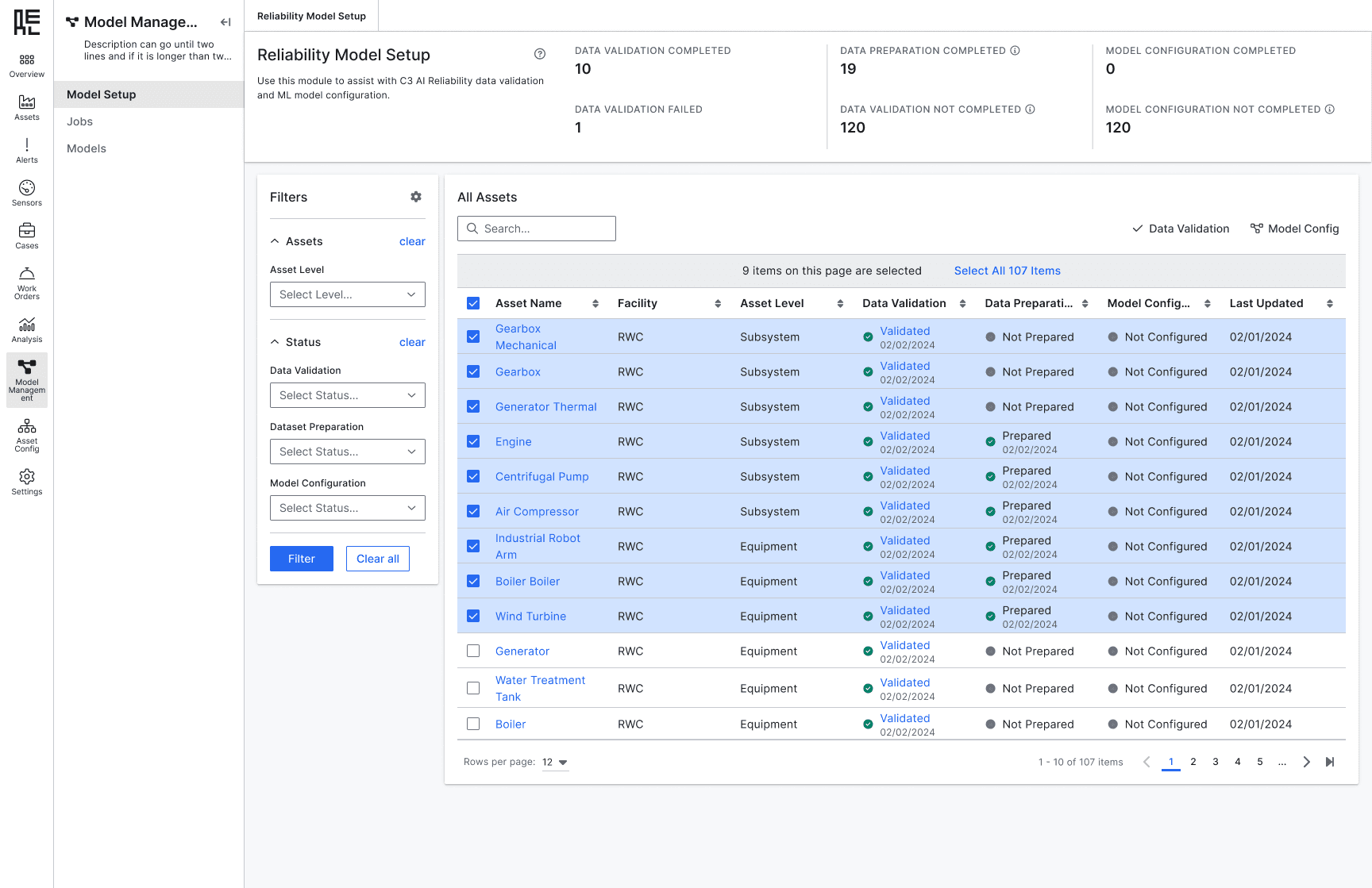
Bulk select assets to start model configuration
Enable users to apply configurations in bulk to multiple assets or datasets, allowing for efficient scaling across assets.
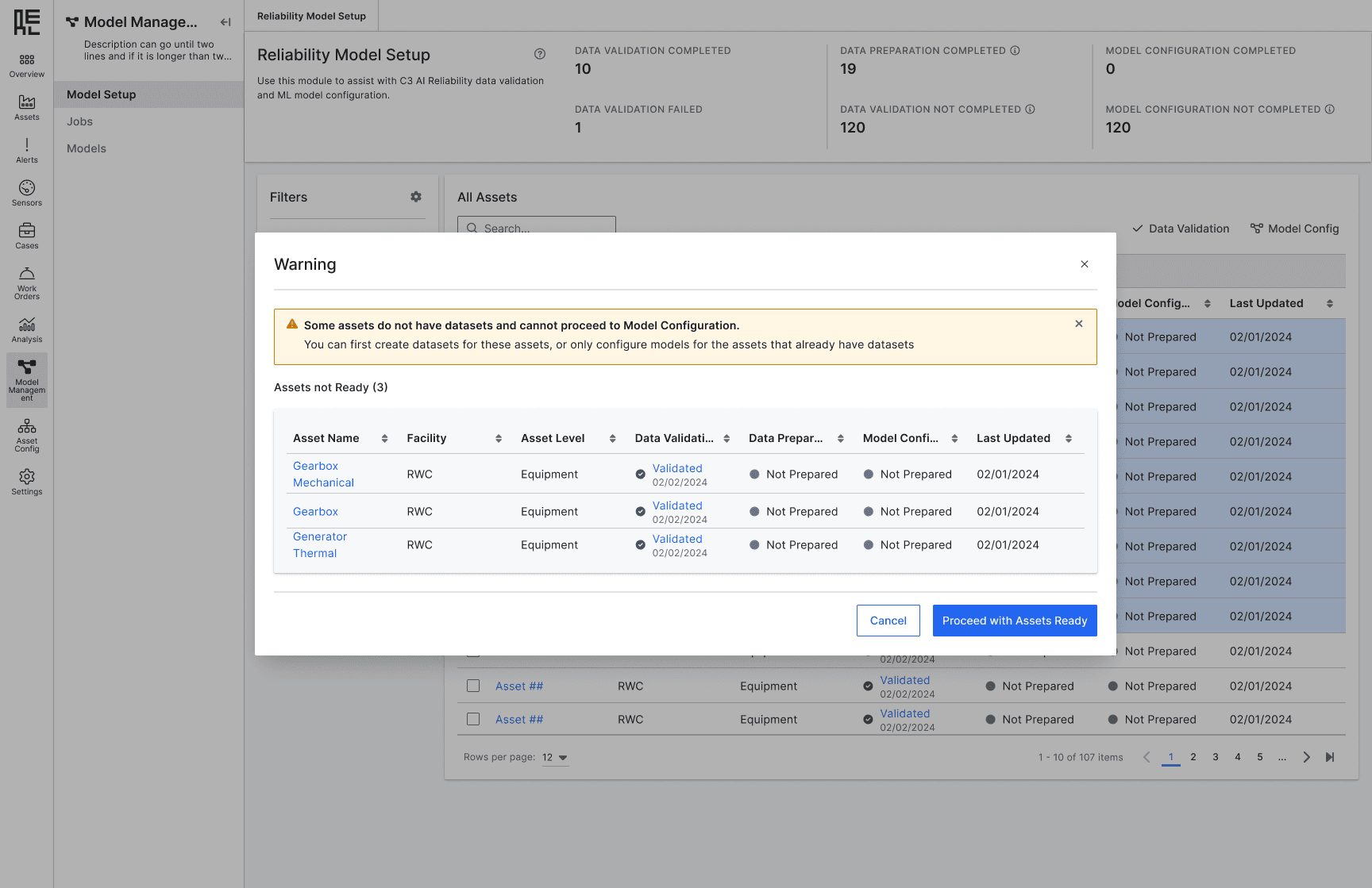
Consider the edge case, give users the flexibility to skip or back
Provide default configurations but with flexibility to adjust
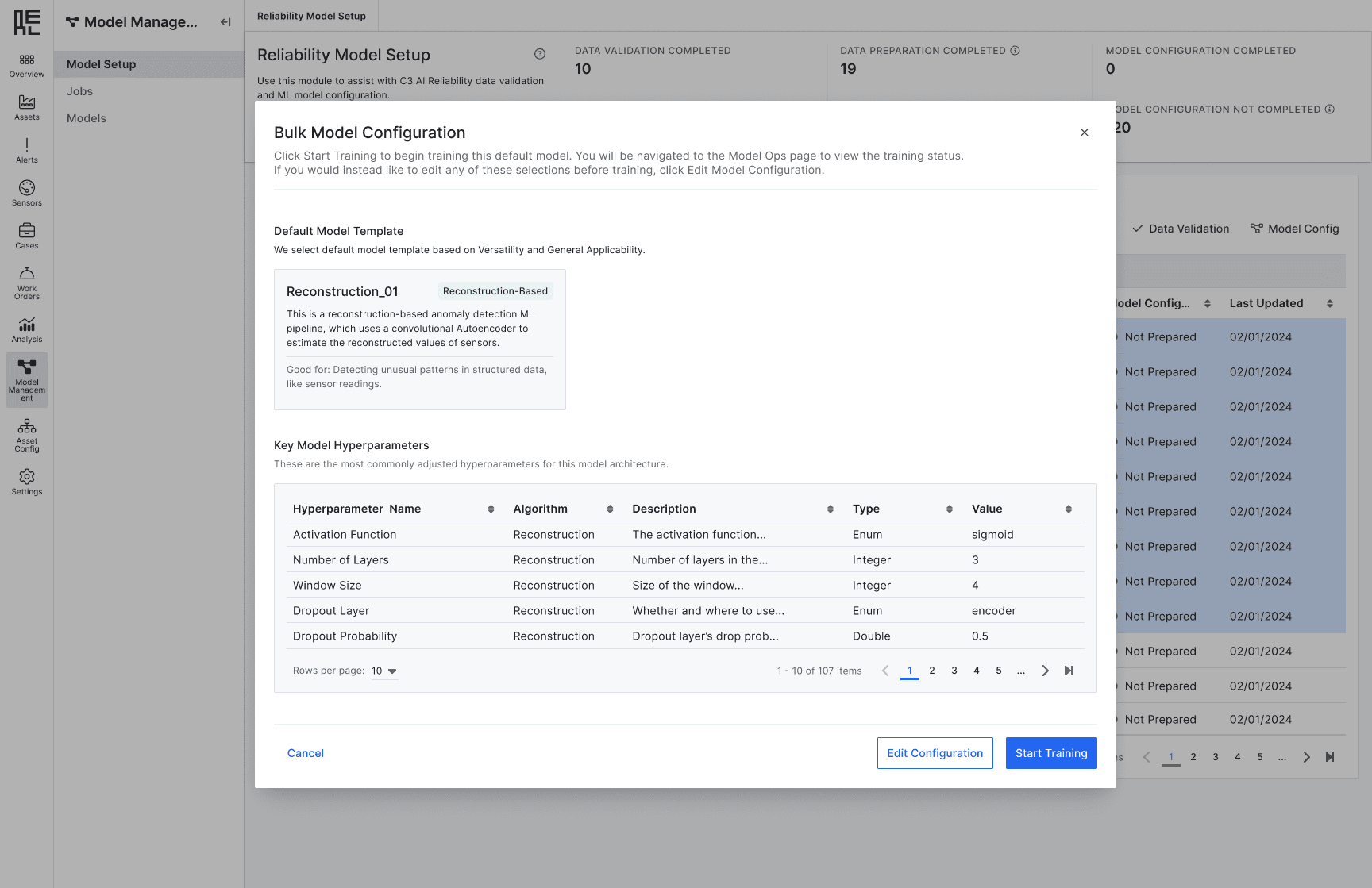
Default Configuration
Streamlined one-click solution to minimize cognitive load
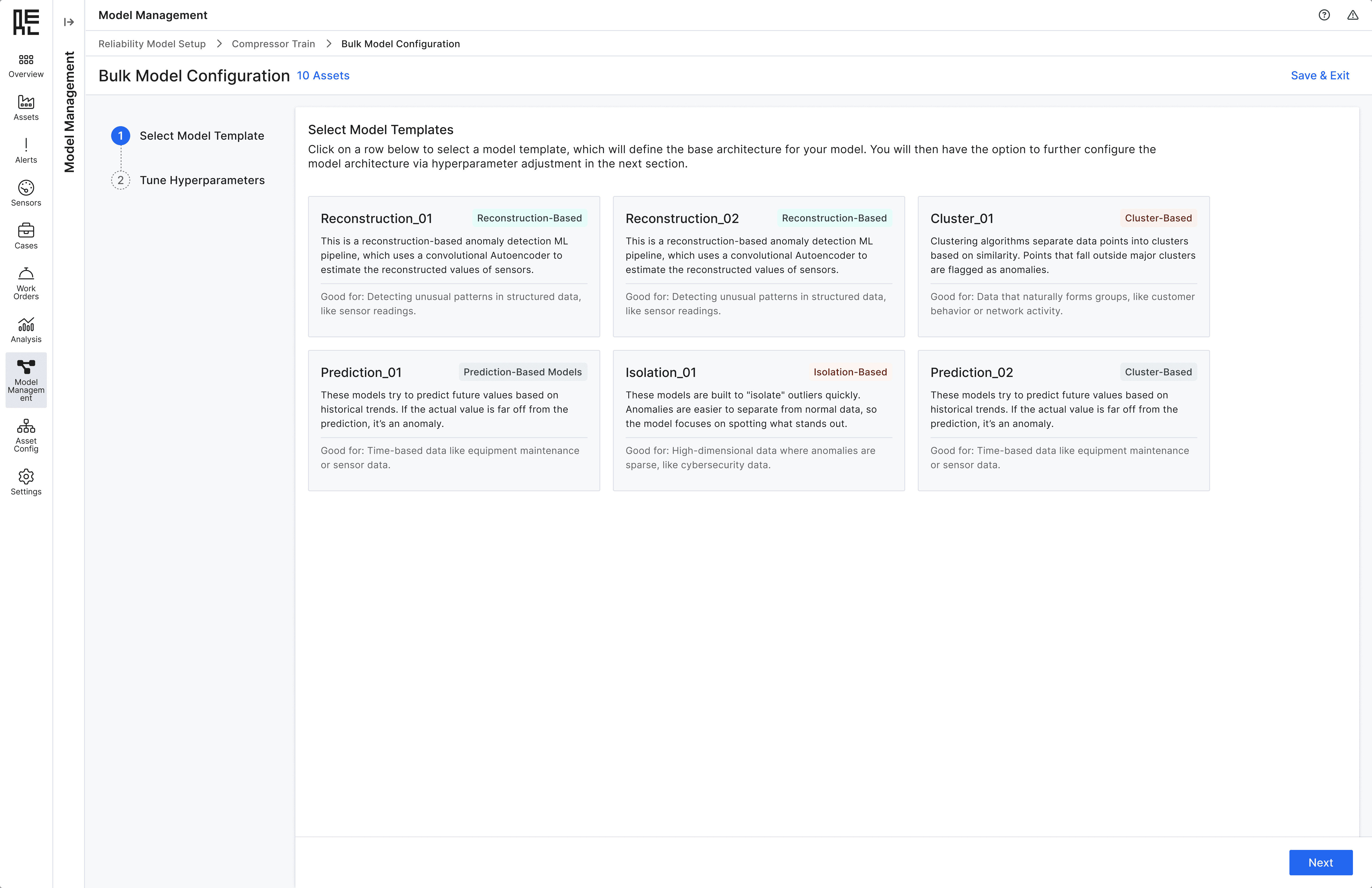
Configurable Templates
Provide pre-set templates that users can apply and modify based on typical use cases, speeding up the process while maintaining flexibility.
Impact
Significantly Reduced FTE and Deployment Time with New Feature Release
Thanks for Stopping By
Evie Xu